The Chaotic State of GPU Programming
This is the script of the video available at https://www.youtube.com/watch?v=9-DiGrnz8l8.
GPUs have accelerated advances in artificial intelligence [1], genomics research [2], computer
vision [3], and many other fields by performing some calculations significantly faster than
conventional hardware. And as we keep developing more powerful programs, the demand for GPUs will
keep increasing.
But
GPU programming is a mess. Several frameworks are available to program them, but they are sometimes
locked to specific platforms and often impractical to use. This lack of compatibility and
convenience makes development challenging.
Take llama.cpp [5], a project that lets you run large language models locally and uses GPUs to
accelerate computations. To support multiple platforms, the developers have written seven GPU
backends, each doing pretty much the same computations but targeting different types of devices
and operating systems. Thousands of lines of code have to be maintained for each backend. Clearly,
the GPU programming ecosystem is not ideal for cross-platform support and productivity.
I want to explain three things in this video:
- First, how GPUs work and why they are so powerful.
- Second, how to develop software for GPUs.
- Third, how GPU programming will evolve.
How GPUs Work
If you want to understand how GPUs work, you have to understand parallelism, which consists in
performing calculations simultaneously rather than sequentially. A parallel program divides a
task into smaller sub-tasks that run at the same time or in overlapping stages, which decreases the
total execution time.
Parallelism entails some overhead because the system has to split the data and coordinate the
sub-tasks. For small datasets, the performances gained through parallelism might not make up for
this overhead, so sequential programs are often more efficient in these cases.
Also, parallelism is not equally applicable to all problems. When there is a weak data dependency,
for instance, if you want to increment the elements in an array, the sub-tasks can run separately,
which is simple to program. When there is a strong data dependency, for instance, if you want to
sort the elements in an array, the sub-tasks have to synchronize and exchange data, which is more
difficult to program.
Overall, parallelism really shines when processing large amounts of weakly dependent data. One such
application is computer graphics, where we manipulate millions of pixels independently. GPUs -
graphics processing units, were invented to process images efficiently by using parallelism.
In contrast to CPUs, which contain a small number of powerful cores designed to handle different
tasks separately, a GPU contains a large number of weaker cores designed to execute the same
function on different data [6]. This makes GPUs less flexible for general-purpose computing than
CPUs, but more efficient at processing large amounts of data in parallel.
Although they were originally invented to accelerate computer graphics, GPUs have been repurposed
since the early 2000s for other tasks, like linear algebra [7], deep learning [1], and cryptography
[8] - by which I mean mining Bitcoins [9]. But despite their widespread use, programming GPU remains
kind of complicated.
- First, you need to use specialized frameworks to write your code because conventional programming
languages typically lack support for GPUs. - Second, writing code for GPUs is more counterintuitive than writing sequential programs. You need
to account for the memory hierarchy of GPUs and manually balance the computations across the cores
to use the GPU efficiently.
Many projects that use GPUs, like llama.cpp [5] and PyTorch [10] combine two approaches. Most of the
code is written in conventional programming languages, and some heavy calculations are delegated to
a GPU backend.
And that's what we will do now. I've implemented programs that combine conventional programming
languages with GPU programming frameworks to accelerate parallel computations. We'll compare the frameworks,
and you can download the source code to try them out if you want.
GPU Programming
We'll start with graphics application programming interfaces, and the first one we'll see is
Graphics Interface
OpenGL
OpenGL, an API released in 1992 by Silicon graphics and eventually handed over to Khronos Group
[12]. OpenGL standardizes access to GPUs. Instead of writing custom code for each platform, which
was common back then, programmers could use OpenGL to develop cross-platform software.
Creating an application with just OpenGL can be complex, but third-party libraries help simplify
tasks such as window creation and input handling. To render something, we have to create vertices
and feed them to the graphics pipeline, which performs a sequence of operations to convert the
vertices into an image. Most of these operations are handled implicitly by OpenGL, but we have to
explicitly provide two shaders, which are programs intended to run on GPUs to render a scene.
In OpenGL, shaders are written in a language called GLSL [13].
- The vertex shader determines the final position of each vertex. This can be used to
rotate the vertices and project them onto a surface. - The fragment shader processes discrete graphical elements - most of the time, pixels - to
determine their final color. This can be used for texturing and adjusting shades.
The GPU driver compiles the source code of the shaders into machine code that the GPU can run in
parallel. The OpenGL graphics pipeline is relatively simple to use, but since many operations are
handled implicitly, we don't have fine-grained control over its performances. Also, OpenGL was last
updated in 2017 and it does not support modern GPU features like ray tracing.
Graphics are the main use case of OpenGL, but we can also use it for general-purpose computing. A
compute shader is a program designed for parallel execution, similar to the shaders we have
already written, but this one is intended to process data instead of participating in the graphics
pipeline. One thing we have to keep in mind is that the CPU and GPU don't use the same memories, so
we have to call special functions to exchange data between them. This compute shader calculates the
sum of elements in an array by using reduction. Because of the memory transfer overhead, the GPU is
more efficient than the CPU only for large arrays [14].
Overall, OpenGL remains widely supported and used, but more modern options are available if you
target high performances.
DirectX & Metal
While OpenGL is a cross-platform API, Microsoft and Apple have developed their own APIs, DirectX
[15] and Metal [16], which are only supported on their respective platforms.
Like OpenGL, DirectX uses a rendering pipeline to convert the vertices into a 2D image, but this
time, we program the shaders with a different language, HLSL. It also supports general-purpose
computing. DirectX resembles OpenGL for a simple use case, but DirectX is actually more powerful. It
offers explicit control of the memory, which makes it easier to optimize performances, it supports
modern GPU features, and it has a lower driver overhead. Metal is the API developed by Apple. It
uses the MSL shading language and, as DirectX, it offers high performances and versatility. Over
time, the limitations of OpenGL in the face of its competitors became more apparent, so Khronos
Group decided to release its successor, Vulkan, in 2016.
Vulkan
It gives developers explicit control over the GPU, which makes it more powerful, but also more
challenging to use. Remember the OpenGL graphics pipeline? Most of the operations in that pipeline
are handled for us, we just have to implement the shaders. Not in Vulkan: we have to manually define
each step of the pipeline [17]. Also, Vulkan shaders use SPIR-V, which is an intermediate
representation not designed to be human-readable. We have to write our shaders in a human-readable
language, like GLSL, compile them into SPIR-V, and then provide them to the program at runtime.
These design choices give developers more freedom to optimize their programs, but they also entail
more effort. Replicating the OpenGL program we've seen before takes around nine times more lines of
code. The same goes for general-purpose computing: we have to define the entire pipeline to run our
compute shaders, but you can use a framework called Kompute [18] to simplify that.
Using Vulkan is complicated. It offers high performances, but it's clearly not designed for
convenience. Many developers prefer to use DirectX or Metal over Vulkan because they are easier to
use and well supported on Microsoft and Apple systems, respectively. And that's not ideal; you
don't want to maintain separate versions of your code to use the best API for each system,
especially in cross-platform software like Web applications. The World Wide Web Consortium decided
to publish a new API, WebGPU, in 2021 to address these problems [19].
WebGPU
It's actually a successor to an older API called WebGL. WebGPU is a modern, cross-platform API that
is more ergonomic than Vulkan. It also uses yet another shading language: WGSL. Contrarily to what
its name might suggest, WebGPU is not limited to Web applications. We can use it in Web browsers,
but also on desktop. For example, the wgpu project is a Rust library that lets you code GPU
programs with WebGPU. In my use case, I found WebGPU a little more verbose that DirectX, but much
more concise than Vulkan. We also have explicit control over the graphics pipeline, which enables us
to optimize the code more, and it supports compute shaders. WebGPU is still fairly new and not yet
supported on some browsers, but we will see more and more applications using it.
Those were some of the most prominent graphics APIs. In practice, the majority of developers do not
have to use them. For instance, in a game engine or a 3D rendering program, interactions with the
graphics pipeline are typically abstracted and most developers do not have to control them directly.
You only need to use a graphics API when optimizing relatively low-level code.
General-Purpose
Another use case for GPUs is general-purpose computing, like deep learning and physics engines.
Sure, graphics APIs often support these computations, but not always in a very elegant way. Several
frameworks made specifically for general-purpose computing have been developed over the years, and
the big one is CUDA, Nvidia's proprietary framework. It only works on their GPUs, but you can find
unofficial workarounds to run CUDA on other GPUs [20].
CUDA
The basic principle of CUDA is the same as what we've seen so far: we dispatch compute shaders on
the GPU to accelerate parallel computations, only this time, we call them compute kernels. It's
the same thing - a program that runs on a GPU, but it gets another name to emphasize that it's not
part of a rendering pipeline. The code looks like a regular C++ program, but we can use special
keywords and functions to implement kernels and transfer data between devices. Compared to a
graphics API, CUDA is more streamlined. We don't have to set up a pipeline - we just focus on
the kernels [21].
It's difficult to exaggerate the importance of CUDA in GPU programming. A large portion of the AI
models of the last decade have been trained on Nvidia GPUs, and CUDA remains the framework of choice
for many deep learning libraries. Also, Nvidia controls around a large portion of the discrete
GPU market [22]. Many developers focus on supporting CUDA exclusively because of its efficiency and
Nvidia's market presence.
But many devices do not support CUDA, like most cellphones and many desktop computers. Applications
built with CUDA are thus restricted to specific systems and are difficult to ship to a wide
audience. That's generally not a problem for scientific applications, but it is if you're trying
to democratize LLMs, for instance.
OpenCL
OpenCL was basically created as a cross-platform answer to CUDA. It's currently managed by Khronos
Group, but it was originally proposed by Apple, which later deprecated it on their systems in
favor of Metal [23].
OpenCL is similar in use to CUDA. We program compute kernels, this time using the OpenCL C language,
and launch the kernels from the main application. One advantage of OpenCL is that we can run the
kernels not only on GPUs, but also on CPUs and even other types of accelerators, like FPGAs. Some
researchers have found OpenCL to be slower than CUDA, but the difference in performances can be
minimized by optimizing the OpenCL kernels [24].
Regarding the syntax, OpenCL has not changed much over the years. There's been an attempt to make
it more convenient by supporting C++14 features, but these features were made optional in 2020. As
a result, modern OpenCL has not changed much since the 2011 version, but it remains a cross-platform
alternative to CUDA, and serious projects support it.
SYCL
SYCL is another specification by Khronos Group. It's a modern API for general-purpose computing on
GPUs and other types of accelerators. It lets us seamlessly integrate compute kernels inside of C++
code, which can make development and maintenance easier than with OpenCL [25].
ROCm, OneAPI
Apart from Nvidia, other GPU venders have made their own APIs. AMD launched ROCm and Intel, oneAPI.
Both are open-source, which is an advantage compared to CUDA, but their respective companies have a
smaller market presence in the GPU space and their APIs are less established.
So that's the basic picture of the general-purpose computing on GPUs: CUDA is the best API but it's
not cross-platform, and the cross-platform alternatives are not as widely used.
High-Level
A relatively recent trend is to wrap general-purpose computing APIs in high-level interfaces.
Triton
OpenAI developed Triton to help optimize their models [26]. A lot of neural network tasks can be run
in parallel - for instance, the training process makes extensive use of matrix multiplications,
which can be accelerated by orders of magnitude on GPUs. You can design neural networks by combining
existing components in Pytorch or Tensorflow, and while this approach is convenient, it is difficult
to optimize the resulting networks. Triton was made to design neural network by specifying exactly
how the GPU should execute the operations. Since the syntax is more high-level than CUDA, OpenAPI
claims that Triton can achieve higher performances with significantly less programming effort.
The Future of GPU Programming
Let's now see how GPU programming might evolve in the future.
Heterogeneous Computing
GPU programming is part of a larger trend called heterogeneous computing, which consists in
using dedicated hardware to accelerate some tasks. For instance, some phones now include a neural
processing unit to accelerate AI models. These models can run on CPUs or GPUs, but phone vendors
have decided to dedicate specialized hardware for neural networks now that AI applications are
becoming more widespread [28].
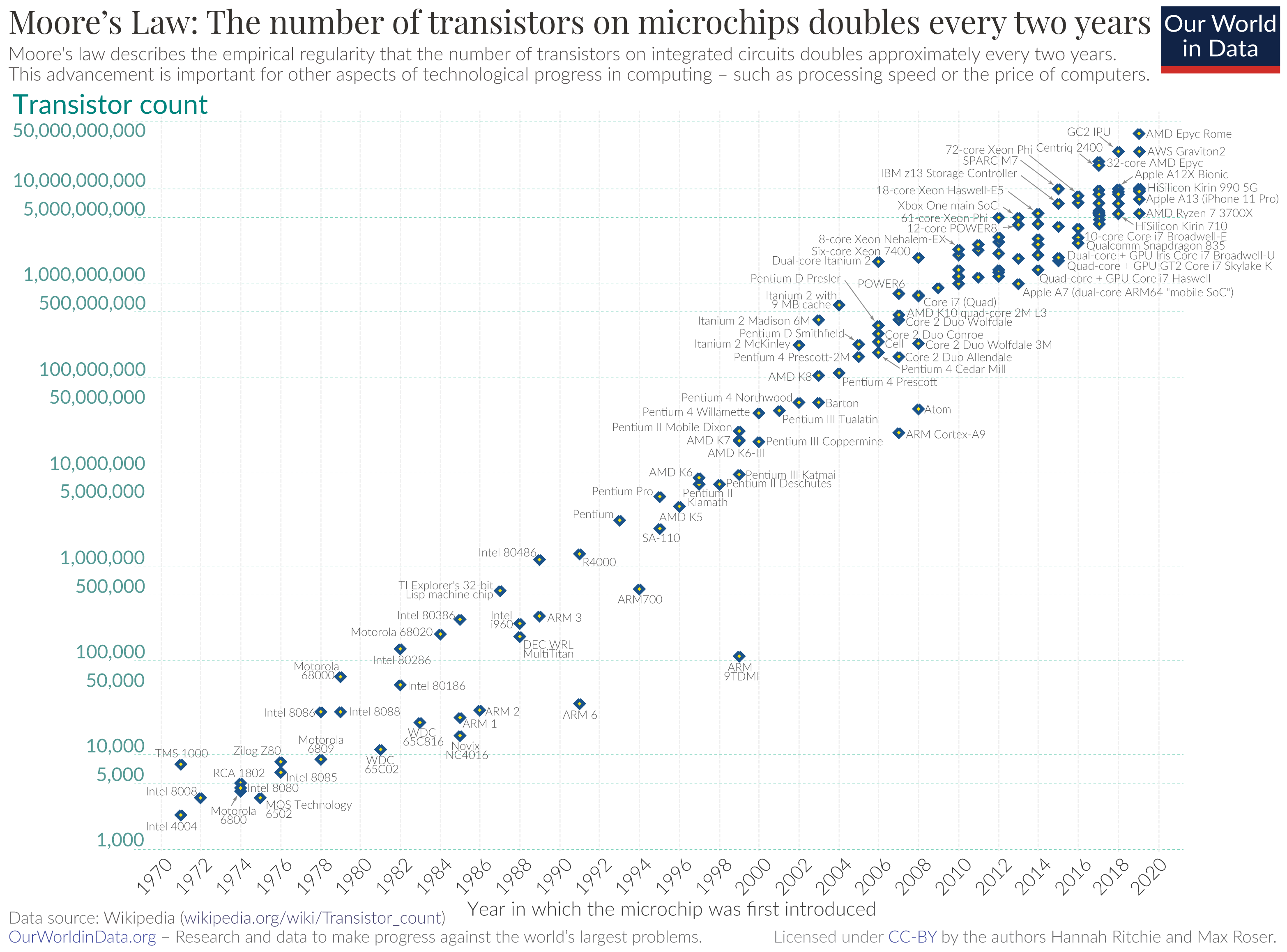
One factor that can explain this trend is the shift in Moore's law. The number of transistors on
chips has historically increased exponentially, but that pace has slowed down in recent years. We
can no longer expect hardware to keep improving as fast as before, and, as a result, heterogenous
computing might become more frequently used to accelerate programs.
Productivity
Improving cross-platform support could help developers use GPUs more efficiently. Several
frameworks are locked to specific devices and operating systems, which forces developers to
re-implement their algorithms. Cross-platform frameworks like WebGPU could help avoid these
situations [29].
Another interesting innovation is the integration of accelerated operations into regular code. Most
of the time, when you want to execute code on GPU, you have to program shaders or kernels in
specific language, like GLSL or WGSL, and this separation of GPU and CPU code makes the programs
more complex to maintain. SYCL and Triton are interesting approaches: they let you integrate
GPU-accelerated operations seamlessly into regular code. Similar projects are in development.
rust-gpu, for instance, lets you write shaders directly into Rust code, but the project is not
production-ready yet [30].
I said that GPU programming is a mess, and - while I still think that incompatibility issues are
really cumbersome, trying our these frameworks made me realize that their diversity has fostered
innovation. Recent frameworks let you code more efficiently than ever, and I think that they will
continue to improve and make GPU programming even more convenient and powerful.
References
- [1] Raina et al. "Large-scale Deep Unsupervised Learning using Graphics Processors" (2009) http://robotics.stanford.edu/~ang/papers/icml09-LargeScaleUnsupervisedDeepLearningGPU.pdf
- [2] Schatz et al. "High-throughput sequence alignment using Graphics Processing Units" (2007) https://pmc.ncbi.nlm.nih.gov/articles/PMC2222658/pdf/1471-2105-8-474.pdf
- [3] Afif et al. "Computer vision algorithms acceleration using graphic processors NVIDIA CUDA" (2020) https://link.springer.com/article/10.1007/s10586-020-03090-6
- [4] Removed. Used to point at https://www.statista.com/statistics/1166028/gpu-market-size-worldwide/
- [5] Gerganov and contributors. "llama.cpp" https://github.com/ggml-org/llama.cpp
- [6] Caulfield. "What’s the Difference Between a CPU and a GPU?" (2009) https://blogs.nvidia.com/blog/whats-the-difference-between-a-cpu-and-a-gpu/
- [7] Krüger and Westermann. "Linear algebra operators for GPU implementation of numerical algorithms" (2003) https://dl.acm.org/doi/10.1145/882262.882363
- [8] Manavski. "CUDA Compatible GPU as an Efficient Hardware Accelerator for AES Cryptography" (2007) https://ieeexplore.ieee.org/abstract/document/4728256
- [9] Osborne. "Cryptocurrency miners bought 3 million GPUs in 2017" (2018) https://www.zdnet.com/finance/blockchain/cryptocurrency-miners-bought-3-million-gpus-in-2017/
- [10] PyTorch, a deep learning library https://github.com/pytorch/pytorch
- [11] Removed. Used to point at https://www.tensorflow.org
- [12] Khronos Group. "History of OpenGL" https://www.khronos.org/opengl/wiki/History_of_OpenGL
- [13] Khronos Group. "Rendering Pipeline Overview" https://www.khronos.org/opengl/wiki/Rendering_Pipeline_Overview
- [14] Khronos Group. "Compute Shader" https://www.khronos.org/opengl/wiki/Compute_Shader
- [15] Microsoft. "Direct3D 12 graphics" https://learn.microsoft.com/en-us/windows/win32/direct3d12/direct3d-12-graphics
- [16] Metal, by Apple https://developer.apple.com/documentation/metal/
- [17] Vulkan specification https://docs.vulkan.org/spec/latest/chapters/pipelines.html
- [18] Kompute, a Vulkan-based general-purpose GPU programming framework https://github.com/KomputeProject/kompute
- [19] WebGPU, by the W3C https://www.w3.org/TR/webgpu/
- [20] Zuhair. "NVIDIA CUDA Can Now Directly Run On AMD GPUs Using The 'SCALE' Toolkit" (2024) https://wccftech.com/nvidia-cuda-directly-run-on-amd-gpus-using-scale-toolkit/
- [21] CUDA, by Nvidia: https://cuda-tutorial.readthedocs.io/en/latest/tutorials/tutorial01/
- [22] Khan. "NVIDIA’s AIB Market Share Grows To 90% As Total GPU Shipments Declined By 14.5% In Q3 2024" (2024) https://wccftech.com/nvidia-aib-market-share-grow-90-percent-total-gpu-shipments-decline-q3-2024/
- [23] "Khronos Launches Heterogeneous Computing Initiative" (2008) https://web.archive.org/web/20080620123431/http://www.khronos.org/news/press/releases/khronos_launches_heterogeneous_computing_initiative/
- [24] Fand et al. "A Comprehensive Performance Comparison of CUDA and OpenCL" (2011) https://ieeexplore.ieee.org/document/6047190
- [25] SYCL, by Khronos Group: https://www.khronos.org/sycl/
- [26] OpenAI. "Introducing Triton: Open-source GPU programming for neural networks" (2021) https://openai.com/index/triton/
- [27] Removed. Used to point at https://github.com/HigherOrderCO/Bend
- [28] IBM. "What is a neural processing unit (NPU)?" https://www.ibm.com/think/topics/neural-processing-unit
- [29] burn, a deep learning framework: https://github.com/tracel-ai/burn
- [30] rust-gpu: a Rust GPU programming framework https://github.com/Rust-GPU/rust-gpu
- [31] Godot documentation. "Internal rendering architecture". https://docs.godotengine.org/en/stable/contributing/development/core_and_modules/internal_rendering_architecture.html
- [32] Ritchie and Roser. "Moore's Law: The number of transistors on microchips doubles every two years" https://assets.ourworldindata.org/uploads/2020/11/Transistor-Count-over-time.png
{kind=link}